
GRÁFICAS DE ESTADÍSTICAS
El título de cada gráfica de este estudio de la inteligencia con un enfoque a la familia nos indica a qué variable del coeficiente de inteligencia de los progenitores (R o M & P) se refieren las correlaciones. Estas correlaciones están representadas en cada vértice o punto gordo de las líneas de colores correspondiente a las distintas variables de los hijos (H) objeto de análisis e indicadas en la cajita de la parte derecha de la gráfica.
Asimismo, en la parte izquierda del gráfico se sitúan las variables formadas por las distintas agrupaciones de 1 a 10 valores de los 70 cocientes de inteligencia (CI) existentes para cada una de las variables del modelo de datos originales, tanto de los progenitores como de los hijos, y sin orden conocido. En la parte derecha se encuentran los grupos con los mismos tamaños, pero con los valores ordenados previamente a su agrupación con la variable mencionada al pie del mismo como criterio estadístico de ordenación.
En definitiva, se consigue una percepción casi instantánea no solo de la bondad del modelo de datos sino de la tendencia y posibilidades de mejora de 60 o más coeficientes de determinación (r²). Todo ello ha permitido el calcular y valorar aproximadamente unos 500 millones de coeficientes de correlación en el conjunto del Estudio EDI.
Estudio de la inteligencia - Metodología de la investigación estadística
PROCESOS DE VALIDACIÓN DEL MODELO ESTADÍSTICO DE HERENCIA BIOLÓGICA EN EL DESARROLLO DE LA INTELIGENCIA
1. Generales.
La diferencia observada en la investigación correlacional del modelo de datos con variables de grupos entre datos estadísticos originales previamente ordenados y no ordenados indica con claridad que la reducción del número de elementos de las variables y consiguientemente los grados de libertad del modelo estadístico, cuando los grupos son mayores, no mejora las correlaciones por sí misma.
El incremento de los coeficientes de correlación en el modelo de datos con las variables de grupos con el tamaño de los grupos cuando han sido previamente ordenados los datos estadísticos originales se debe a que tanto las desviaciones inherentes a los test de inteligencia como a las variaciones o diferencias provocadas por la combinación genética mendeliana se compensan en mayor grado y dentro de cada grupo, lo que provoca una más nítida separación de cada escalón.
Con independencia de los buenos ajustes obtenidos en muchos del presente estudio de la evolución de la inteligencia la tendencia a mejorar la correlación de los CI con el tamaño de los grupos hace suponer que, para grupos de 20 elementos y con una muestra mayor, los coeficientes de correlación se podrían situar por encima de 0,9 en todos los casos.
2. Simulación de procesos evolutivos con cocientes artificiales de inteligencia.
El Modelo Social o Modelo Individual debidamente reformulado nos ha servido para determinar que el gen significativo es el de menor potencial. Ahora bien, si el modelo genérico propuesto por la ECV es correcto deberíamos poder realizar una simulación de procesos de validación capaz de crear una variable artificial W de coeficientes de inteligencia que se comportase como los datos estadísticos observados en el estudio longitudinal.
La segunda gran sorpresa, para mí, fue el fracaso del modelo de la inteligencia de grupos simplificado para conseguir este objetivo de simulación de los procesos.
La introducción de la evolución en el sentido aportado por la Teoría de la Evolución Condicionada de la Vida y de la capacidad de generar variables con perturbaciones que las acerquen a las variables reales nos define un nuevo modelo que llamaré Modelo Global para facilitar las referencias a los procesos de validación que implica y el propio razonamiento.
Como sabemos, las diferencias en los valores correspondientes a las mediciones del cociente de inteligencia de las mismas personas pueden ser muy grandes. Sin duda existen desviaciones debidas a la diferente expresión de la capacidad en cada momento, y con mayor motivo, en años diferentes.
Otro factor que provoca o puede provocar el mismo tipo de desviaciones es el test particular utilizado e incluso cada prueba específica dentro de un test de inteligencia estándar.
Consecuentemente, podemos introducir en la simulación estadística un factor adicional de aleatoriedad por estas causas, para mejorar la simulación de los procesos reales. Aunque las diferencias observadas son superiores al 10% respecto de la media en algunos casos, introduciré una desviación media de un 3% hacia arriba y un 3% hacia abajo.
Por la misma razón que he introducido elementos de error en las variables H de los hijos, se debe poner un mismo patrón de error en las variables M de madres y P de padres al realizar la simulación de los procesos en un enfoque a la familia.
Sin embargo, la correlación de la variable objeto de simulación estadística en el Modelo Global no baja de forma importante.
A este respecto, se puede incluir en los procesos de validación del modelo de evolución el interesante efecto filtro sobre la afinidad genética de los progenitores que menciona la citada teoría en cuanto a que el potencial resultante de la combinación genética será igual a la intersección de los potenciales y no al potencial del menor gen o cromosoma.
Otra de las simplificaciones realizadas se refiere al modelo teórico de la Teoría General de la Evolución Condicionada de la Vida., éste nos señala que existe evolución, que efectivamente el medio ambiente influye, pero de una forma más general, es decir, la capacidad se incrementa a lo largo de la vida y se transmite a la descendencia.
A pesar de otros logros, hasta ahora no se han bajado las correlaciones de W de forma satisfactoria.
Definitivamente se necesita algo importante o relevante que baje las correlaciones suficientemente, por eso, después de darle unas cuantas vueltas, he introducido en los procesos de validación a simular lo que denomino limitaciones funcionales debidas a causas diversas, entre las que se puede destacar que existen problemas genéticos.
Por situarlo en algún momento, después de la combinación genética mendeliana y del filtro de afinidad podemos suponer que existen algo así como accidentes o problemas genéticos que disminuyen en 30 puntos los coeficientes de inteligencia esperados. Digo 30 puntos porque es lo que mejor resultado dan los procesos de validación cuantitativa a la vista de las gráficas que se producen.
Al final, se ha conseguido que la variable W no se pueda distinguir de las variables de datos estadísticos de coeficientes de inteligencia observados en el estudio longitudinal.
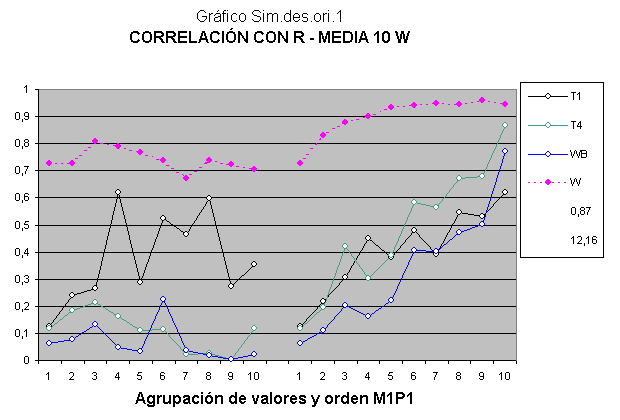
3. Sobre esta gráfica particular del análisis estadístico.
Teniendo en cuenta que W es una variable aleatoria, la gráfica representa la media de 10 estimaciones para las correlaciones correspondientes.
La correlación de la variable de coeficientes artificiales de inteligencia W está muy por encima de las variables naturales, el índice de correlación multidimensional (ICM) se ha multiplicado por 3 a efectos comparativos, es superior a 25