
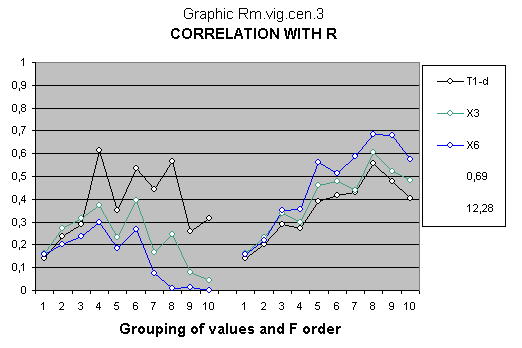
STATISTICAL GRAPH
The title of each graph of the statistical study indicates the parents' variables (R or M & F) to which the correlations relate. Each point of the colored lines represents the correlations with the observational C variables of the children.
Likewise, the variables of unknown order, formed by the different groups of 1 to 10 values from the 70 IQ values of each parent and children variables, appear on the left-hand side of the graph. The criteria order of the groups of 1 to 10 values located on the right-hand side is the variable mentioned at the bottom of the graph.
Indeed, there is an almost instantaneous perception of the exactitude of the particular specification of the statistical study; each graph shows sixty coefficients of determination (r²) highlighting the global and underlying relations of the involved data set.
See the methodology of the statistical abstract for more details
STATISTICAL STUDY COMMENTS
1. General statistical significance
The considerable increase of the correlation for the estimation of homogenous groups is not due to the reduction of 68 to 5 or 4 degrees of freedom, since the estimation with non-homogenous groups, without previous rearrangement, has the same degrees of freedom and the correlation even lowers concerning the sample without grouping.
In general, the model of the genetic evolution of intelligence (Mendelian genetics – Conditional intelligence – Global Cognitive Theory) adjusts perfectly, showing an r² superior to 0.9 in several cases. Bearing in mind the tendency to increase the goodness of fit with the size of rearranged groups, we could assume it would be over 0,9 in almost all the cases for grander groups within a more significant sample.
2. Social Model and evidence of the LoVeInf method
The Social Model shows the criterion of arrangement based on *M1F1 is robust, confirming the behavior predictions derived from the presence of the Logical Verification of Information method (LoVeInf) pointed out by the Conditional Evolution of Life (CEL).
The research uses the rearrangement criterion opposite of *M1F1 to assure the behavior foreseen by the LoVeInf method; that is to say, the order of the vector *2F2M formed by the grater values of M2 and F2.
The result is substantially weaker with *2F2M than with the *M1F1; therefore, we may assume more rigorously that the LoVeInf method is operative in the genetic characters associated with intelligence.
The inclusion of another two rearrangement criteria in the analysis of the centered variables tries to find even more evidence, that is to say, mother’s variable *M and father’s variable *F.
For these two vectors of the progenitors, the results are different, symmetrical and superior compared to those obtained with variable *2F2M, although they are quite inferior in respect to *M1F1.
3. Significant comments on this particular graph
As you can clearly see by its form, the three dependent variables of the children, analyzed in the model, behave in a very similar way to the progenitors' explanatory variable R
The general multidimensional correlation index (GMCI) is 12,28 which is significantly lower than other arrangement criterions. However, it is bigger with centered variables than original variables.
Likewise, the highest determination coefficient r² of this graph is 0,69 which is one of the lowest of The EDI Study, as all the graphs of this statistical research.